进程与线程的区别
- 进程是系统进行资源调度和分配的独立单位;而线程是CPU调度和分配的基本单位。
- 进程间相互独立,享有独立的资源;一个进程内的多个线程可以共享资源,但对于其他进程内的线程是不可见的。
- 进程间可以通过管道、消息队列、信号量、共享内存、信号、套接字等IPC机制来通信;线程间可以直接访问全局变量等共享的内存,但需要一定的同步和互斥手段。
- 切换线程的开销要比切换进程的开销小很多。
- 进程的内存布局是分代码段、数据段、堆区、MMAP段、栈区,而线程栈在堆区和栈区中间的MMAP段。
- 另外线程使用的结构体跟进程相同,都是task_struct,线程可以共享进程的堆数据、文件描述符等各种资源。
- 一个进程中可以有多个线程。
进程与线程的关系可以看成下面这样:
1
2
3o |======
|======
|------举例说明两者的区别
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19一个进程可以类比成一个车间,多进程就是多个车间。
每个线程相当于车间内的一条生产,多线程就是一个车间内有多条生产线。
不同车间之间需要运送货物,可以人工搬运、传送带、货车等,
相当于进程间管道、消息队列、共享内存等IPC通信。
每个车间内有需要加工的材料,不同生产线都可以使用这些材料,
相当于线程间可以共享进程的一些资源,比如堆区数据、文件描述符等,
于是产生了资源争用,需要一些同步互斥的手段。
这个工厂内只有一个工人,就相当于CPU,他可以选择去不同的生产线去工作,
在不同的生产线之间切换,就相当于cpu的时间片轮转。
工人每次只能在一条生产线工作,代表对于内核来说,只有线程的概念,而没有进程的概念。
工人在不同生产线之间切换是相对容易的,不同车间之间的切换是比较麻烦的。
一个车间发生了事故,另一个车间一般还能继续工作。
而一条生产线发生事故,其他生产线可能就会受影响。
进程间通讯有哪些
1.管道
- 面向字节流,创建匿名管道的时候使用int pipe(int fd[2]),产生两个文件描述符,从fd[0]读出数据,从fd[1]写入数据,然后fork进程,就可以实现两个进程间的通讯。
- 优点是使用简单。
- 缺点是必须A全部写完,B才能读取数据,效率不高,不适合频繁的交换数据。
2.消息队列
- 消息队列是保存在内核中的消息链表,在发送数据时,会分成一个一个独立的数据单元,也就是消息体(数据块),消息体是用户自定义的数据类型,消息的发送方和接收方要约定好消息体的数据类型,所以每个消息体都是固定大小的存储块,不像管道是无格式的字节流数据。
- 优点是能够频繁通讯。
- 缺点是(1)数据量大了,用户态和内核态之间拷贝数据的时间比较多,(2)并且对消息体的大小和队列长度有限制,所以也不适合大数据量的进程间通讯。
3.共享内存
- 因为不同的进程都有自己的虚拟空间,它的原理是让不同进程的虚拟空间指向相同的物理内存,这样不同进程都可以共享这块物理内存。适合进程间共享大块数据的情况。
- 优点是数据量大的情况下效率仍然比较高。
- 缺点是需要同步互斥机制保证数据的安全。
4.信号量
- 信号量本身不用来传递数据,可以用来对共享内存进行同步互斥的控制。信号量定义了两种操作,分别是P(申请资源)、V(释放资源)。(进程通讯使用的有名信号量,以一个设备文件形式存在。)
5.信号
- 信号是进程间通信机制中唯一的异步通信机制,一旦有信号产生,可以执行默认操作、可以执行设定的信号处理函数、可以忽略信号(有两个信号是应用进程无法捕捉和忽略的,即 SIGKILL 和 SEGSTOP)。
6.socket
- 套接字可以实现不同主机间的进程通讯,也可以进行本地进程间通讯。
参考:https://mp.weixin.qq.com/s/MnIcTR0KKpgnSoA3xaPUSA
fork、vfork、clone
1.在创建新的进程时,fork函数会复制父进程的所有资源,包括打开的文件描述符、信号处理函数、虚拟页、物理数据页、页表等,后来添加了写时复制,fork时就不用复制父进程的数据页了,等到其中一个进程执行写操作,就将该资源复制一份。
2.vfork是专门为exec而生的,很多时候复制一个新的进程后,接着就调用exec加载新进程了,这样复制的资源就浪费了。vfork复制的资源更少,并且执行后会保证子进程先执行,并且等到执行exec或者exit之后才会让父进程执行。
3.clone函数能够指定创建新进程时复制哪些资源。
4.进程包含的资源主要是物理内存的数据量较大,其中原始fork和写时复制fork分别如下: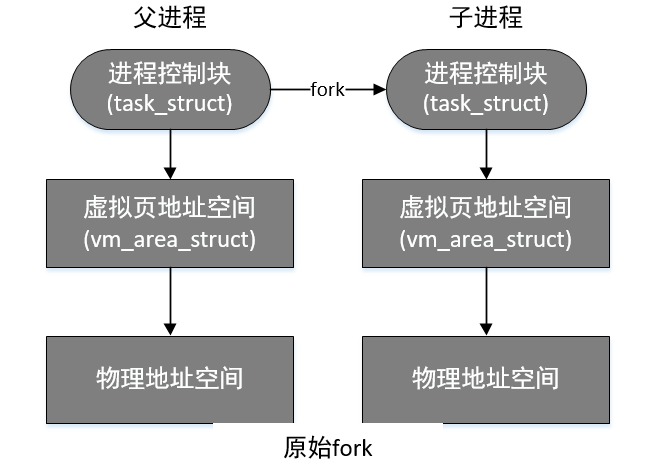
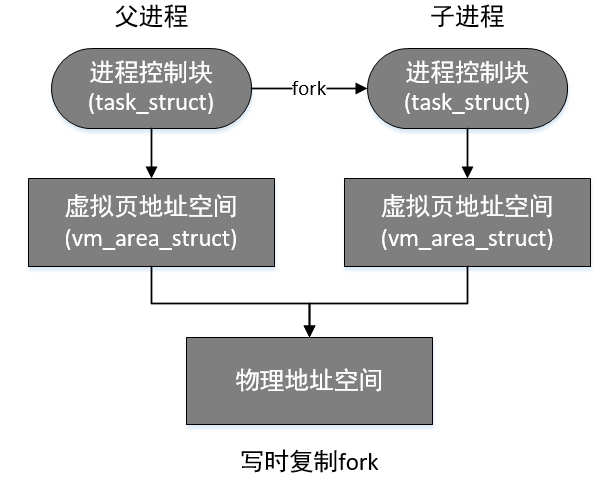
vfork的流程图如下: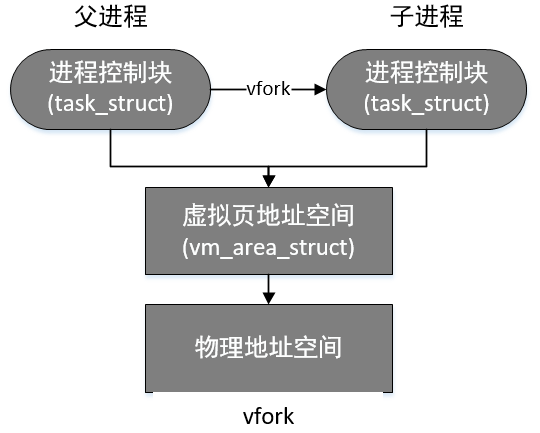
5.fork的具体工作如下:
1 | 功能总结: |
进程状态机
1.三态模型:1
2
3就绪←→运行
↖ ↙
阻塞
2.五态模型:1
2
3新建→就绪←→运行→终止
↖ ↙
阻塞
3.实际系统的7态:
- TASK_RUNNING可运行状态,进程要么在CPU运行了,要么就准备运行。
- TASK_INTERRUPTIBLE可中断的等待状态,进程执行sleep或者等待某些系统资源会进入该状态,直到某个条件变为真或者资源获得了,重新进入可运行状态。
- TASK_UNINTERRUPTIBLE不可中断的等待状态,很少使用的状态,当进程访问某个设备文件时,驱动程序会去探测硬件,驱动程序此时就处于这种状态,不能被中断。
- TASK_STOPPED暂停状态,当进程收到SIGSTOP、SIGTSTP、SIGTTIN、SIGTTOU信号后会进入暂停状态。
- TASK_TRACED跟踪状态,gdb就借助了ptrace系统调用,被别的进程跟踪后的进程处于跟踪状态。
- EXIT_ZOMBIE僵死状态,当子进程结束,父进程没有调用wait4或waitpid进行回收,子进程会变成僵尸进程,处于僵死状态。
- EXIT_DEAD僵死撤销状态,父进程调用wait后,会进入该状态,是为了避免父进程中有第二个线程,调用wait函数回收该进程。
守护进程、孤儿进程与僵尸进程
- 守护进程:守护进程就是在后台运行,不与任何终端关联的进程,通常情况下守护进程在系统启动时就在运行,它们以root用户或其他特殊用户运行,并能处理一些系统级的任务。
- 孤儿进程:父进程退出,而它的一个或多个子进程还在运行,那么那些子进程将成为孤儿进程。孤儿进程将被父进程(一般是进程号为1的init进程所收养,并由父进程对它们完成状态收集工作。
- 僵尸进程:一个进程使用fork创建子进程,如果子进程退出,而父进程并没有调用wait或waitpid获取子进程的状态信息,那么子进程的进程描述符仍然保存在系统中并占用系统资源,这种进程称之为僵尸进程。
进程调度算法
进程终止的五种方式
- 正常退出
- 从main函数返回
- 调用exit
- 调用_exit
- 异常退出
- 调用abort 产生SIGABOUT信号
- 由信号终止 ctrl+c SIGINT
多线程间同步方式
1.mutex,互斥锁,用来保证资源只能同时被一个线程获取。
2.条件变量,与互斥锁结合使用。
3.读写锁,多个读操作之间是不互斥的,写操作与其他任何操作都互斥。
4.信号量,线程同步是使用的匿名信号量,导入信号量头文件,然后创建信号量变量。
一个进程可以创建多少线程,和什么有关?
- 通过ulimit -a 查看线程的栈大小,用户空间的内存除以栈大小是可创建线程的最大数量。
五种IO模型
- 阻塞IO、非阻塞IO、IO复用、信号驱动IO、异步IO
如何理解阻塞和非阻塞,同步与异步?
举例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15老张爱喝茶,废话不说,煮开水。
出场人物:老张,水壶两把(普通水壶,简称水壶;会响的水壶,简称响水壶)。
1.老张把水壶放到火上,立等水开(同步阻塞),老张觉得自己有点傻。
2.老张把水壶放到火上,去客厅看电视,时不时去厨房看看水开没有。(同步非阻塞)老张还是觉得自己有点傻,于是变高端了,买了把会响笛的那种水壶。水开之后,能大声发出嘀~~~~的噪音。
3.老张把响水壶放到火上,立等水开。(异步阻塞)老张觉得这样傻等意义不大.
4.老张把响水壶放到火上,去客厅看电视,水壶响之前不再去看它了,响了再去拿壶。(异步非阻塞)老张觉得自己聪明了。
所谓同步异步,只是对于水壶而言。普通水壶,同步;响水壶,异步。
虽然都能干活,但响水壶可以在自己完工之后,提示老张水开了。这是普通水壶所不能及的。
同步只能让调用者去轮询自己(情况2中),造成老张效率的低下。
所谓阻塞非阻塞,仅仅对于老张而言。立等的老张,阻塞;看电视的老张,非阻塞。
情况1和情况3中老张就是阻塞的,媳妇喊他都不知道。
虽然3中响水壶是异步的,可对于立等的老张没有太大的意义。
所以一般异步是配合非阻塞使用的,这样才能发挥异步的效用。
来源:https://www.zhihu.com/question/19732473/answer/23434554IO & 进程线程
1
xxx
参考:https://www.zhihu.com/question/19732473/answer/241673170
页表为什么要分级
1.首先页表分级能够节省存储空间。因为虚拟地址空间比实际的物理内存要大许多,但是一个进程可能只用到一部分虚拟地址,如果存储所有虚拟地址到物理地址的一一映射,那就会浪费空间。采用多级页表之后,只有一级页表直接被创建,只有用到的二级页表,才会分配空间来存储。
2.一级页表需要常驻内存,二级页表可以调入或调出到磁盘存储。
3.举例:如果虚拟地址位数是10位,一个进程只能用到10%的虚拟地址。采用一级页表,我们需要2^10=1024个页表项。采用5|5的二级页表,就只需要2^5+1024*10%=32+102=134个页表项。
页面置换算法
最佳置换算法(opt),这是一个无法实现的理论上最优的算法,因为每次缺页时需要判断哪个页面在之后最长时间内都不会被访问。
假如按照如下顺序访问内存页:7, 0, 1, 2, 0, 3, 0, 4, 2, 3, 0, 3, 2, 1, 2, 0, 1, 7, 0, 1。1
2
3
4
5
6
7访问页 7 0 1 2 0 3 0 4 2 3 0 3 2 1 2 0 1 7 0 1
一号页 7 7 7 2 2 2 2 2 7
二号页 0 0 0 0 4 0 0 0
三号页 1 1 3 3 3 1 1
缺页否 √ √ √ √ √ √ √ √ √
缺页9次,置换6次。先进先出置换算法(FIFO:first in first out),这也是最简单的页面置换算法,基本思想是:当需要淘汰一个页面时,总是选择驻留时间最长的页面进行淘汰,即按照先入先出的规则来淘汰。
1
2
3
4
5
6
7访问页 7 0 1 2 0 3 0 4 2 3 0 3 2 1 2 0 1 7 0 1
一号页 7 7 7 2 2 2 4 4 4 0 0 0 7 7 7
二号页 0 0 0 3 3 3 2 2 2 1 1 1 0 0
三号页 1 1 1 0 0 0 3 3 3 2 2 2 1
缺页否 √ √ √ √ √ √ √ √ √ √ √ √ √ √ √
缺页15次,置换12次最近最久未使用算法(LRU:Least Recently Used)
1
2
3
4
5
6
7访问页 7 0 1 2 0 3 0 4 2 3 0 3 2 1 2 0 1 7 0 1
一号页 7 7 7 2 2 4 4 4 0 1 1 1
二号页 0 0 0 0 0 0 3 3 3 0 0
三号页 1 1 3 3 2 2 2 2 2 7
缺页否 √ √ √ √ √ √ √ √ √ √ √ √
缺页12次,置换9次
LeetCode 146. LRU Cache1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41static int __=[](){std::ios::sync_with_stdio(false);return 0;}();
class LRUCache {
public:
LRUCache(int capacity) {
pageNumber=capacity;
}
//如果访问页在内存中,返回其value并更新该key。如果访问页不在,返回-1。
int get(int key) {
auto it=pageToCache.find(key);
if(it==pageToCache.end()){
return -1;
}
pair<int,int> tmp=*(it->second);
cache.erase(it->second);
cache.push_front(tmp);
pageToCache[key]=cache.begin();
return tmp.second;
}
//如果要设置的页不在内存,则插入该页,并判断是否超出限制。如果该页在内存,则更新该页。
void put(int key, int value) {
auto it=pageToCache.find(key);
pair<int,int> tmp(key,value);
if(it!=pageToCache.end()){
(*(it->second)).second=value;
cache.erase(it->second);
cache.push_front(tmp);
pageToCache[key]=cache.begin();
}else{
cache.push_front(tmp);
pageToCache[key]=cache.begin();
if(cache.size()>pageNumber){
pageToCache.erase(cache.back().first);
cache.pop_back();
}
}
}
private:
list<pair<int,int>> cache;
unordered_map<int,list<pair<int,int>>::iterator> pageToCache;
int pageNumber;
};
- 最少使用算法(LFU:least frequently used)
LeetCode 460 LFU Cache: https://leetcode.com/problems/lfu-cache/submissions/1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61struct Node{
int key;
int val;
int freq;
Node(int k,int v,int f):key(k),val(v),freq(f){}
};
class LFUCache {
public:
LFUCache(int _capacity):minfreq(0),capacity(_capacity) {}
int get(int key) {
if(capacity==0) return -1;
auto it=cache.find(key);
if(it==cache.end()) return -1;
int val=it->second->val,freq=it->second->freq;
freq_page[freq].erase(it->second);
if(minfreq==freq && freq_page[freq].size()==0) minfreq++;
freq_page[freq+1].push_front(Node(key,val,freq+1));
cache[key]=freq_page[freq+1].begin();
return val;
}
void put(int key, int value) {
//如果容量为0,则退出
if(capacity==0) return ;
auto it=cache.find(key);
//如果hash表中没有该key,需要添加当前key value
if(it==cache.end()){
//如果当前容量满了,需要先删除访问频率最小的那页,再添加新页
if(cache.size()==capacity){
int lastkey=freq_page[minfreq].back().key;
freq_page[minfreq].pop_back();
if(freq_page[minfreq].size()==0) minfreq++;
cache.erase(lastkey);
}
//添加新的一页
freq_page[1].push_front(Node(key,value,1));
minfreq=1;
cache[key]=freq_page[1].begin();
}else{ //如果hash表中有该key,则更新其value,跟get()操作相似
int freq=it->second->freq;
freq_page[freq].erase(it->second);
if(minfreq==freq && freq_page[minfreq].size()==0) minfreq++;
freq_page[freq+1].push_front(Node(key,value,freq+1));
cache[key]=freq_page[freq+1].begin();
}
}
private:
int minfreq;
int capacity;
unordered_map<int,list<Node>::iterator> cache;
unordered_map<int,list<Node>> freq_page;
};
/**
* Your LFUCache object will be instantiated and called as such:
* LFUCache* obj = new LFUCache(capacity);
* int param_1 = obj->get(key);
* obj->put(key,value);
*/
https://leetcode-cn.com/problems/lfu-cache/solution/lfuhuan-cun-by-leetcode-solution/
死锁产生的四个条件
- 互斥:某种资源一次只允许一个实体访问。
- 不可抢占:别人已经占用了资源,你无法因为自己需要就将资源抢过来。
- 占有且等待:一个进程或线程本身占有了一定资源,同时还有资源未得到满足,正在等待其他进程释放资源。
- 循环等待:发生死锁时,有一个这样的进程链:p1在等待p2占用的资源,p2在等待p3占用的…pn在等待p1占用的资源。
处理死锁的四个方法
预防死锁
破坏产生死锁的一个或几个条件。避免死锁
银行家算法死锁的检测
死锁定理:当某状态的资源分配图是不可完全简化的,说明发生了死锁。死锁的解除
1.抢占资源
2.终止进程
信号量以及PV原语
1.信号量表示资源的数量,控制信号量的方式有两种原子操作:
一个是 P 操作,这个操作会把信号量减去 -1,相减后如果信号量 < 0,则表明资源已被占用,进程需阻塞等待;相减后如果信号量 >= 0,则表明还有资源可使用,进程可正常继续执行。
另一个是 V 操作,这个操作会把信号量加上 1,相加后如果信号量 <= 0,则表明当前有阻塞中的进程,于是会将该进程唤醒运行;相加后如果信号量>0,则表明当前没有阻塞中的进程;
2.如果信号量资源数初始化为1,则为互斥信号量。初始化为0,则为同步信号量。
银行家算法
生产者消费者问题
1.用记录型信号量解决
- 由于生产者消费者可能会同时访问缓冲池,所以需要一个mutex信号量来实现对缓冲池的互斥访问。
- 为了实现同步,可以设置empty,full两个信号量,分别表示空缓冲池和满缓冲池的数量。
- 实现同步为什么需要两个信号量呢?因为生产者受资源满的制约,如果资源满了,就不能再生产了。消费者受资源空的制约。如果只用一个信号量,表示资源数量,资源为空时,消费者可以被阻塞,当资源满时,生产者仅靠PV操作是无法判断的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30int in=0,out=0;
item buffer[n];
semaphore mutex=1,empty=n,full=0;
void producer(){
do{
producer an item nextp;
...
P(empty); //使empty减1;
P(mutex); //同步互斥一块出现时同步在前。(如果先获得锁,接着在P操作阻塞了。消费者就会在获取锁的时候也阻塞)
buffer[in]=nextp;
in=(in+1)%n;
V(mutex); //mutex+1;
V(full);
}while(true)
}
void consumer(){
do{
P(full);
P(mutex);
nextc=buffer[out];
out=(out+1)%n;
V(mutex);
V(empty);
consummer the item in mutex;
...
}while(true);
}
//注意两个程序中的加锁操作(P操作)不能颠倒,否则可能引起进程死锁,解锁顺序无所谓。
哲学家进餐问题
题意:有五个哲学家,喜欢思考问题,思考完了就会饿,然后就要吃饭。现在有5个哲学家围坐在圆桌上,每个人右手边有1根筷子,每个哲学家需要获取左右手边的两根筷子才能吃面条。
方案一:这是很容易想到的方法,每个人先拿左手边筷子,再拿右手边筷子。但是可能会发生死锁。1
2
3
4
5
6
7
8
9
10
11
12
13
semaphore chopstick[5]; //对应5根筷子的信号量,初值为1.
void philosopher(int i){ //i是哲学家编号,0-4
while(true){
think(); //思考
P(chopstick[i]); //取左手边筷子
P(chopstick[(i+1)%N]); //取右手边筷子
eat(); //吃饭
V(chopstick[i]); //放下左手边筷子
V(chopstick[(i+1)%N]); //放下右手边筷子
}
}
当所有人同时拿起左手边筷子时,就会发生死锁。
方案二:为了改进方案,可以加一个mutex,每次只让一个哲学家取筷子。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
semaphore chopstick[5]; //对应5根筷子的信号量,初值为1.
semaphore mutex; //*互斥信号量,初值为1
void philosopher(int i){ //i是哲学家编号,0-4
while(true){
think(); //思考
P(mutex); //*进入临界区,加锁
P(chopstick[i]); //取左手边筷子
P(chopstick[(i+1)%N]); //取右手边筷子
eat(); //吃饭
V(chopstick[i]); //放下左手边筷子
V(chopstick[(i+1)%N]); //放下右手边筷子
V(mutex); //*退出临界区解锁
}
}
但是这种方案同一时刻只能有一个人吃饭,其他人都看着,效率有点低。
方案三:对方案一再次改进,可以每次让奇数号哲学家“先拿右边筷子,再拿左边筷子”,让偶数号哲学家“先拿左边筷子,再拿右边筷子”。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
semaphore chopstick[5]; //对应5根筷子的信号量,初值为1.
void philosopher(int i){ //i是哲学家编号,0-4
while(true){
think(); //思考
if(i%2==0){
P(chopstick[i]); //取左手边筷子
P(chopstick[(i+1)%N]); //取右手边筷子
}else{
P(chopstick[(i+1)%N]); //取右手边筷子
P(chopstick[i]); //取左手边筷子
}
eat(); //吃饭
V(chopstick[i]); //放下左手边筷子
V(chopstick[(i+1)%N]); //放下右手边筷子
}
}
方案四:之前的信号量都是是对应5根筷子的,也可以添加一个state数组标记5个哲学家的状态,当哲学家A想要用餐时,需要先判断左右两边的人是不是思考状态,如果都是思考状态,就拿起两根筷子。这样哲学家拿两根筷子的动作就成了原子的。另外state数组是临界资源,访问的时候需要互斥,所以再添加一个mutex互斥信号量。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
int state[N]; //记录5根筷子的状态
semaphore mutex; //访问state需要的互斥锁,初值为1
semaphore s[5]; //每个哲学家一个信号量,初值为0.(可以将哲学家左右两根筷子看做一个整体)
void test(int i){//尝试让i号哲学家拿起两根筷子
if(state[i]==HUNGRY && state[LEFT]!=EATING && state[RIGHT]!=EATING){
state[i]=EATING; //条件符合,设置为进餐状态
V(s[i]); //表示i号哲学家的两根筷子都能拿了
}
}
void take_chopstick(int i){ //取筷子
P(mutex);
state[i]=HUNGRY; //修改自己为饥饿状态
test(i); //尝试取筷子
V(mutex);
P(s[i]); //没有筷子则阻塞,有筷子就获取筷子进餐。
}
void put_chopstick(int i){ //放下筷子
P(mutex);
state[i]=THINKING; //设置自己为思考状态
test(LEFT); //通知左边的人尝试进餐
test(RIGHT); //通知右边的人尝试进餐
V(mutex);
}
void philosopher(int i){
while(true){
think(); //思考
take_chopstick(i); //取两根筷子
eat(); //进餐
put_chopstick(i); //放下两根筷子
}
}
读者写者问题
题意:读者只会读取数据,写者可以读数据也可以修改数据。(该模型为数据库访问建立了模型)
读者写者可能有以下三种状态:1
2
3
4
5读-读 允许,同一时刻可以有多个读操作
读-写 互斥,同一时刻只能有一个主体去写。
一个读者或写者在读操作,另一个写者就不能去写。
一个写者在写,其他读者和写者就不能去读。
写-写 互斥,同一时刻只能一个写者在写。
xxxxxx
参考:https://mp.weixin.qq.com/s?__biz=MzUxODAzNDg4NQ==&mid=2247485264&idx=1&sn=78585cbabd1e0c333b43a3abd2b2ff64&scene=21#wechat_redirect
http://c.biancheng.net/cpp/html/2601.html
欢迎与我分享你的看法。
转载请注明出处:http://taowusheng.cn/